Libelle BusinessShadow®High availability
With our Libelle BusinessShadow® solution for disaster recovery and high availability, you can mirror databases and other application systems with a time delay. Your company is thus protected not only from the consequences of hardware and application errors, but also from the consequences of elemental damage, sabotage, or data loss due to human error.
Our patented and dynamically adjustable time funnel temporarily stores the change logs before they are mirrored to the standby-system. Switching over to this system in the event of an error or even maintenance can thus be carried out with impressive speed and without any fuss.
Productive database mirrored in 4 hours - with the help of Libelle DBShadow, an international retail group was able to master this challenge
Libelle BusinessShadow® automatically creates the standby-system. The sequences for switching to emergency mode as well as switching back to normal mode can be initiated automatically or at the push of a button. Our high availability and disaster recovery software – impressively fast and simple.
Our software protects against the consequences of both physical influences and logical errors and thus ensures a significantly higher overall availability of your system.
As a single-source solution, our high availability and disaster recovery software can be integrated into both SAP and other application systems. Even in complex and independent application environments, our proven solution consistently mirrors applications, databases, and file systems at the logical level, independent of distance.
After the initial copy, Libelle BusinessShadow® only mirrors the change logs of the production system, which first enter the dynamic time funnel. This means you can provide a functioning standby-system in just a few minutes.
The creation of the database mirror, the archive file shipping, and the time-delayed recovery are carried out automatically by Libelle BusinessShadow®. The production and standby-systems and all processes are also permanently monitored. In the event of an error, you are immediately alerted by a visual alarm. A comprehensive high availability and disaster recovery solution so you can concentrate on your regular tasks.
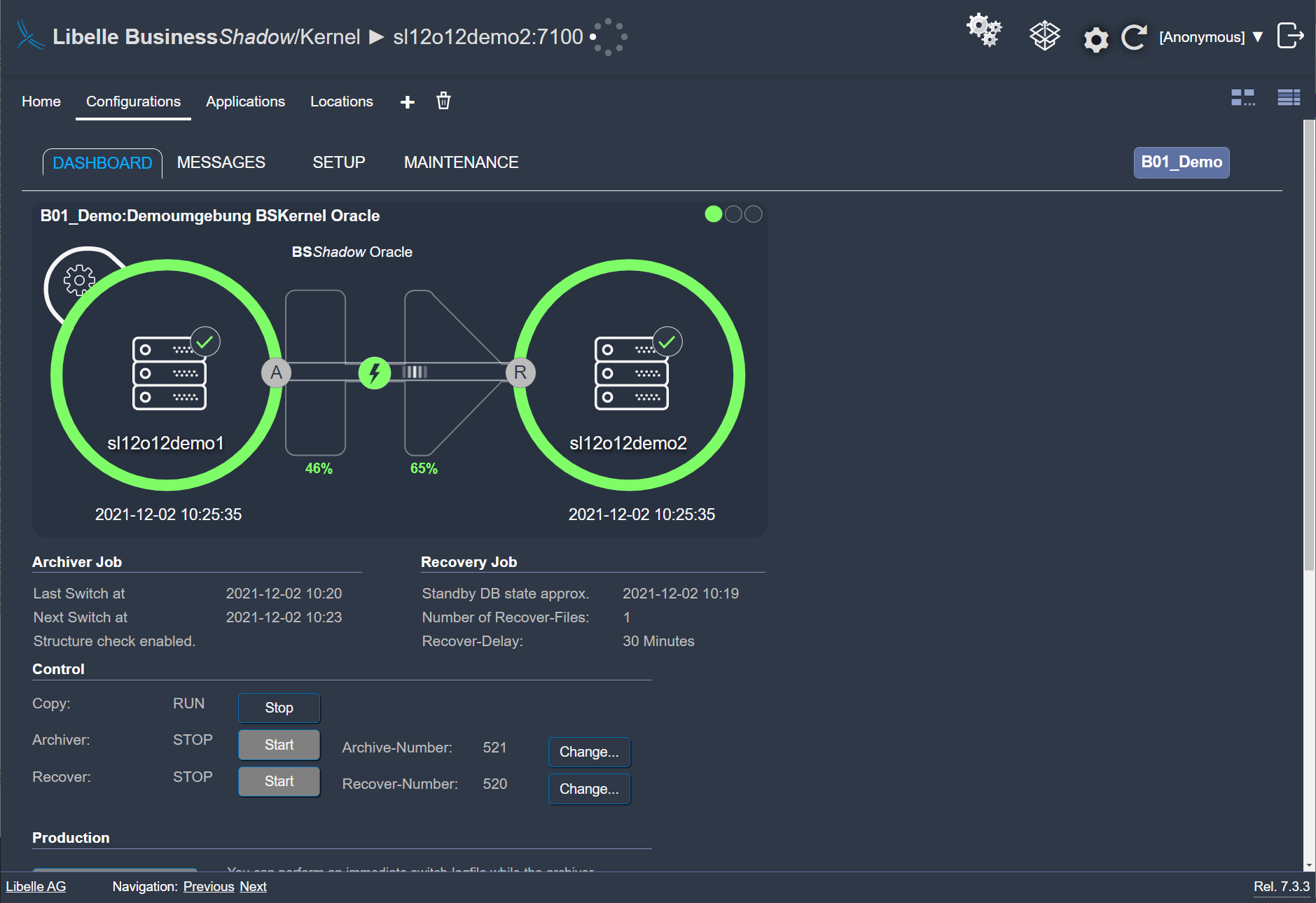
In this phase, Libelle BusinessShadow® automatically copies all data of the production system initially to the standby-system. We take this time to then enable high availability and disaster recovery quickly, safely, and easily with our patented time funnel. This is because only the changes to the production system in comparison to the initial copy are queried and entered into the time funnel by means of our archiver.
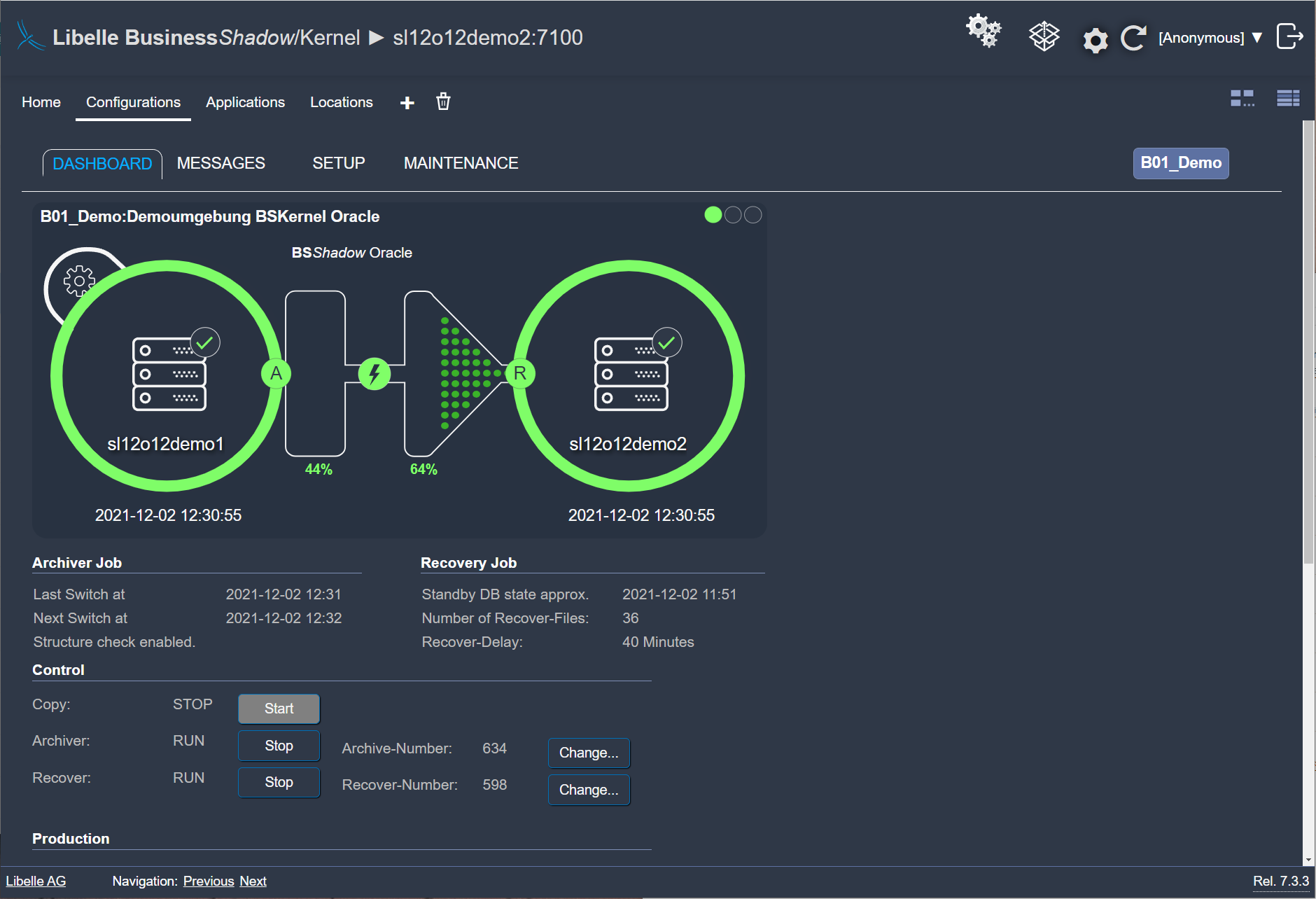
With our high availability and disaster recovery software and its unique time funnel, you have a time safeguard. Before new data is transferred to the standby-system, it is first held in the time funnel. You can determine the duration individually. In the event of errors on the production system, the data is not immediately transferred to the standby system, giving you the chance to activate this failover system at a desired time within minutes. Your backup operating system is available, and you can continue to work without interruption.
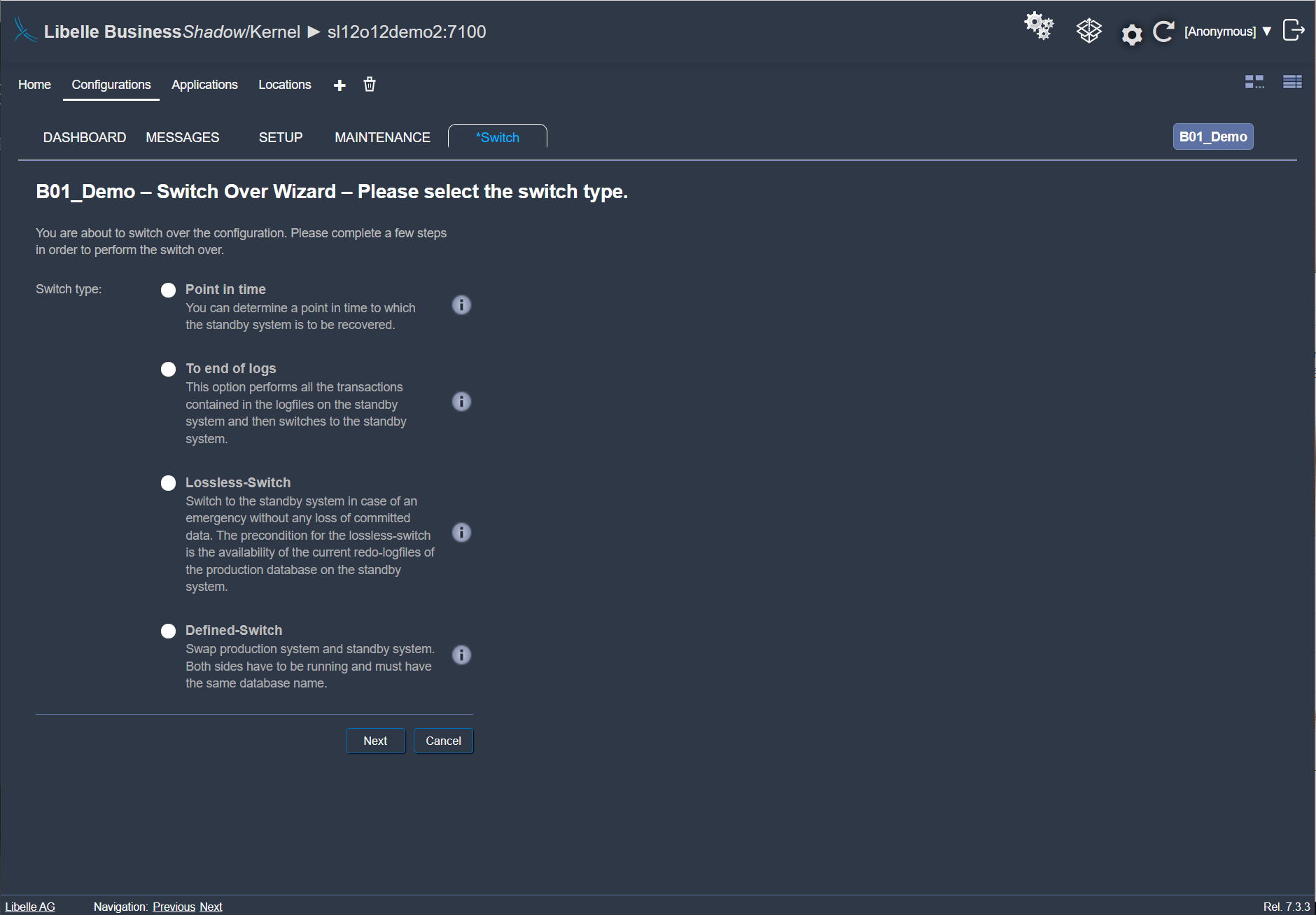
When an error has occurred on the production system - by software, users, or batch jobs - this change log lands in the time funnel. You can now switch to the standby-system, manually or automatically. With Libelle BusinessShadow® you provide a system within a few minutes that has all current data up to shortly before the error occurred. Your company can now continue to work quickly and without issues on the standby-system.
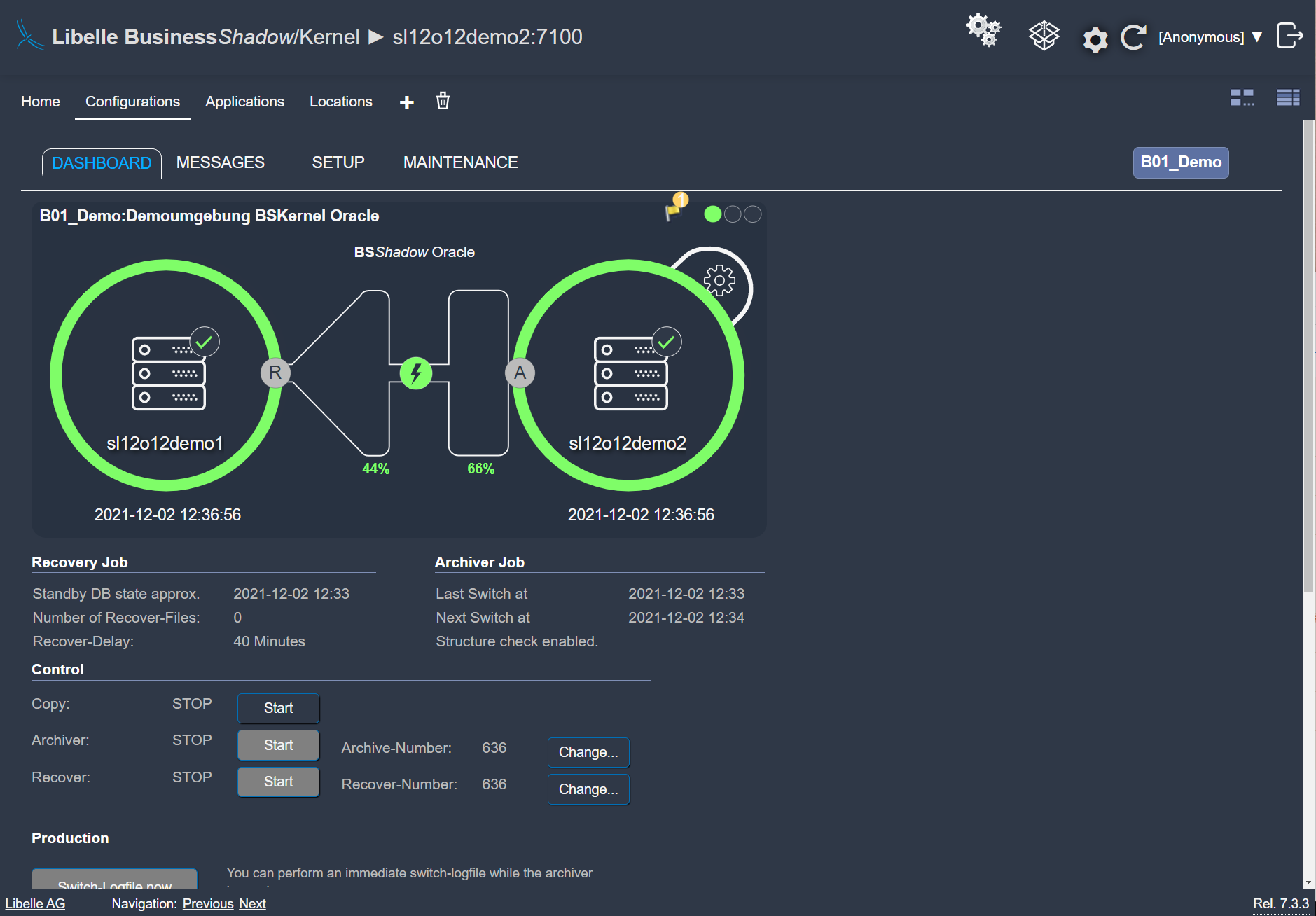
While your business operations continue as normal on the standby-system within a few minutes, your IT team has time to fix the error on the actual production system. Afterwards, you can automatically transfer the current and consistent data from the standby-system back to the production system, and your disaster recovery and availability concept starts again.
