Why is performance important in data masking?
The goal of data masking is to obfuscate data that is deemed sensitive in non-productive systems to reduce risk and follow regulatory and compliance requirements. Data is physically replaced with non-sensitive data following defined patterns to retain the structure and essence of the original data, but without risk of real data exposure. It is applied on production support systems for testing and development, or for data warehouses and analytics systems.
Masking - Step by Step
Data masking is done on an ad-hoc basis, typically when a test system is built with or refreshed from non-masked production data. Assuming a database is being masked one could look at a simplified workflow of masking as three steps:
- Read data from the database
- Obfuscate the data
- Write obfuscated data back to the database
When masking a few thousand records, performance is not an issue. However, most masking projects require the obfuscation of many hundreds of millions, sometimes billions of rows of sensitive data. If there are more than a few million records, any sequential execution for each row of read, obfuscate, and write will run for days, if not weeks.
Data Masking Works Efficiently with Parallelization and Multi-threading
Libelle implemented an intelligent, multi-threaded architecture to push the performance to its absolute peak. Databases are built explicitly to process millions of read and write operations in parallel. Sending sequential reads and writes to a database is like your favorite online retailer operating a single truck with one box at a time going back and forth between destinations – nonsensical. Rather, the logistics infrastructure can handle thousands of vehicles, and each vehicle can take hundreds of boxes. The same is true for the process of masking data.
The Libelle DataMasking Multi-Threading Architecture
Below is a diagram of how Libelle designed and operates the multi-threaded architecture. It is built into the architecture of the Libelle platform that is used to run the Libelle DataMasking server.
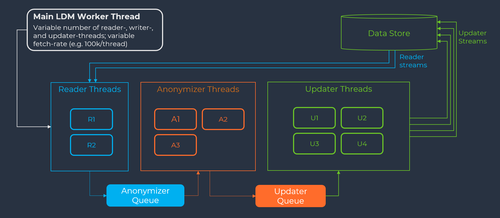
At the beginning of each execution, the administrator can adjust the fetch rate. By default, the fetch rate is set at 100,000 records at a time, whereby a record typically represents one row in a database. That means that each thread contains 100k rows.
The masking configuration already contains the table and fields that require masking. With that information, the Reader Threads begin to read 100k records at a time from the database. A good starting point is typically two reader threads (2RT) to read data, pull data into the masking server, and place the read data into the Anonymizer Queue.
Once data hits the Anonymizer Queue, data is masked by the masking server with the respective algorithm(s), still with 100k records for each thread. Here, names are changed, numbers regenerated, addresses altered, etc. Anonymizing may take more time than reading, so in this case three anonymizer threads (3AT) is a good starting point.
After each thread in the Anonymizer Queue completes, the data enters the Update Queue. Here data is written back to the database, still with 100k records for each thread. Writing into the database may be more expensive resource-wise, so four updater threads (4UT) is a good starting point.
The default configuration of 2RT / 3AT / 4UT can be adjusted to any number desired, based on the unique needs of individual data stores.
Extreme Performance
We need to complete masking swiftly, as the end-users need their analytics or test system back as soon as possible. Multi-threading has one amazing advantage: the workload can be spread across multiple CPUs and, depending on the database, sometimes even multiple database nodes.
Think of a cloud environment where you can temporarily move the workload to larger machines. Why not move the test environment temporarily to a 512 vCPU / 2TB memory workhorse on a public cloud of your choice, execute masking, and move back to your smaller test server?
More Information about Libelle DataMasking
Libelle IT Group has developed Libelle DataMasking, a software solution for the required anonymization and pseudonymization. The solution was designed to produce anonymized, logically consistent data on development, test, and QA systems across all platforms.
The anonymization methods used deliver realistic, logically correct values that can be used to describe relevant business cases and test them in a meaningful end-to-end manner. Furthermore, developers as well as users are provided with a "clean" database with which they do not have to worry about data protection.
Recommended article
All blog articles