Libelle DataMasking
With Libelle DataMasking we provide data masking software to anonymize sensitive and personal data and work with it sensibly - whether in SAP® or another environment. Realistic-looking and GDPR-compliant data replaces the data in your non-production systems during anonymization.
You will be able to mask production data in a way that developers can easily access development or test systems and train participants. Analyses by experts remain meaningful despite anonymized data, as referential integrity is ensured after the data has been masked.
You can try out the demo version of Libelle DataMasking all by yourself — for free and at any time!
How Libelle DataMasking made data anonymization enormously easier for a customer in the banking industry. One billion data records consistently and securely anonymized in under six hours.
Our data masking software works at database level, so we manage to anonymize up to 200,000 data entries per second. If that is not fast enough, tables can also be anonymized in parallel.
Libelle DataMasking provides over 40 anonymisation algorithms and a reference database with defined target values as standard. However, if you wish to adjust your data masking software to your needs, you can also adapt everything here as required.
We transform original production data into realistic-looking and logically correct data. You can thus realistically test, train, and evaluate on your non-production systems – without a concrete personal reference.
Libelle DataMasking can access any common database and be used as a data masking tool for individual systems or complete system landscapes. Databases in different environments are recognized and anonymized across systems.
We are constantly developing our data masking software and responding to the needs of our customers. With the latest release, we have introduced a test run before the actual work steps. This simulates a complete anonymization down to the actual changes in the data. This allows you to test all critical processes in advance and correct errors before you let the anonymization run automatically overnight or over the weekend.
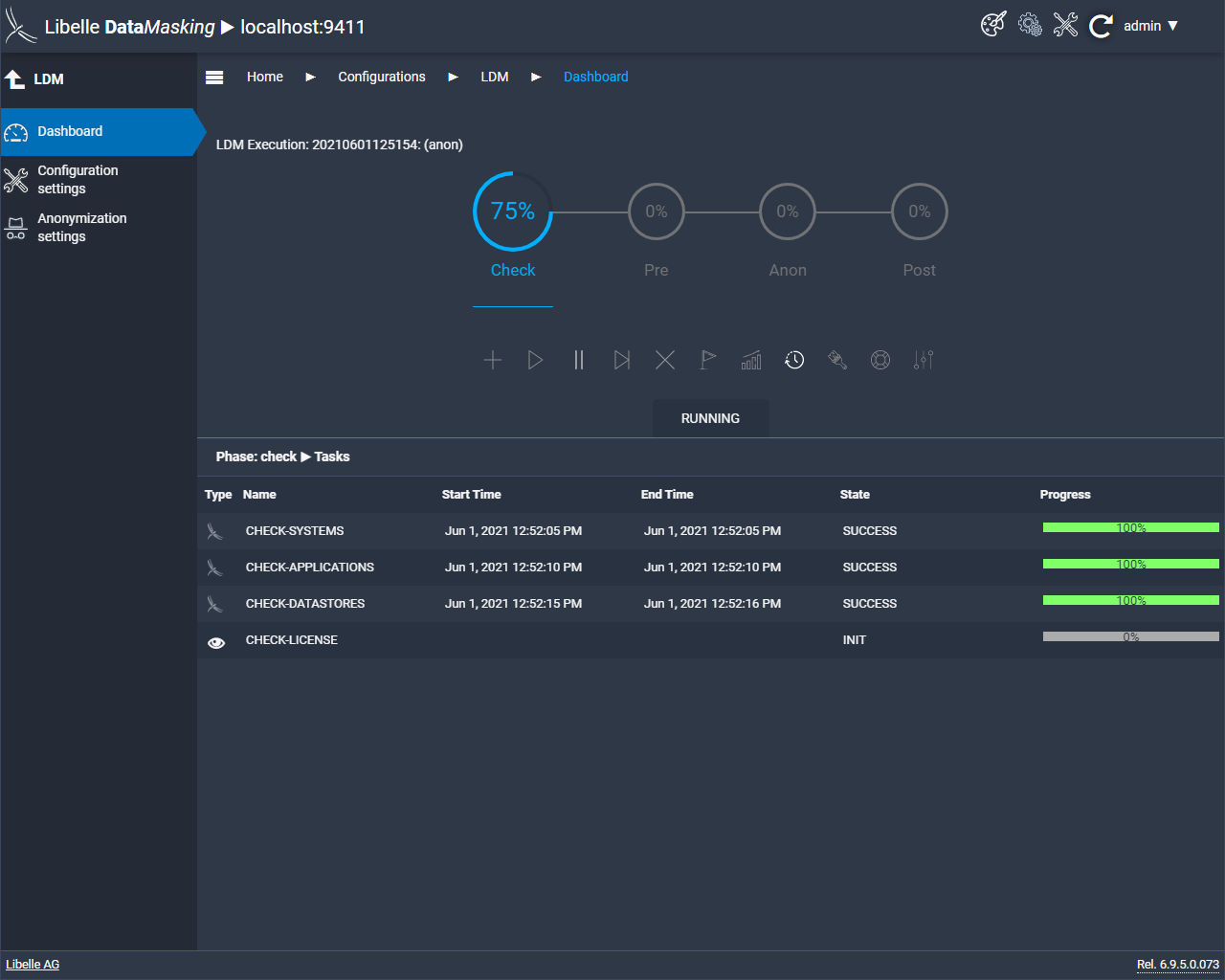
In the check phase, Libelle DataMasking checks the infrastructure of your IT and whether the target system is available. Especially for SAP environments, it ensures that the system is not on production. This is done fully automatically and is an important step in order to take full advantage of our data masking software. Errors or fields that were not recognized can then be easily corrected.
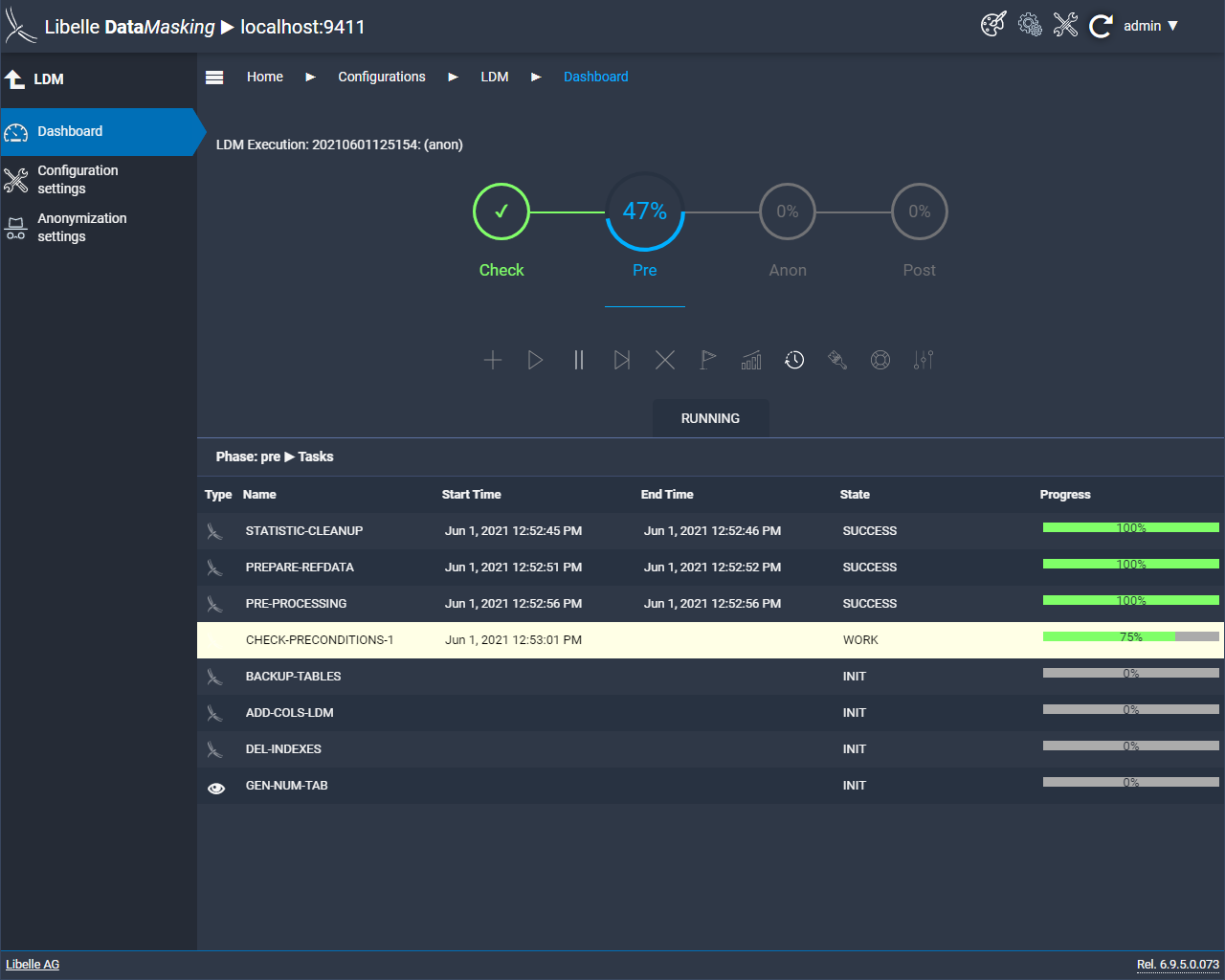
After the successful check, the next step is the pre-phase. Here, the supplied reference files are provided and the keys for anonymization are generated. If necessary, you can also create backup tables here. This is a further facilitation that comes with our data masking software before your first anonymization. If this has not been done according to your wishes, you can fall back on the backups.
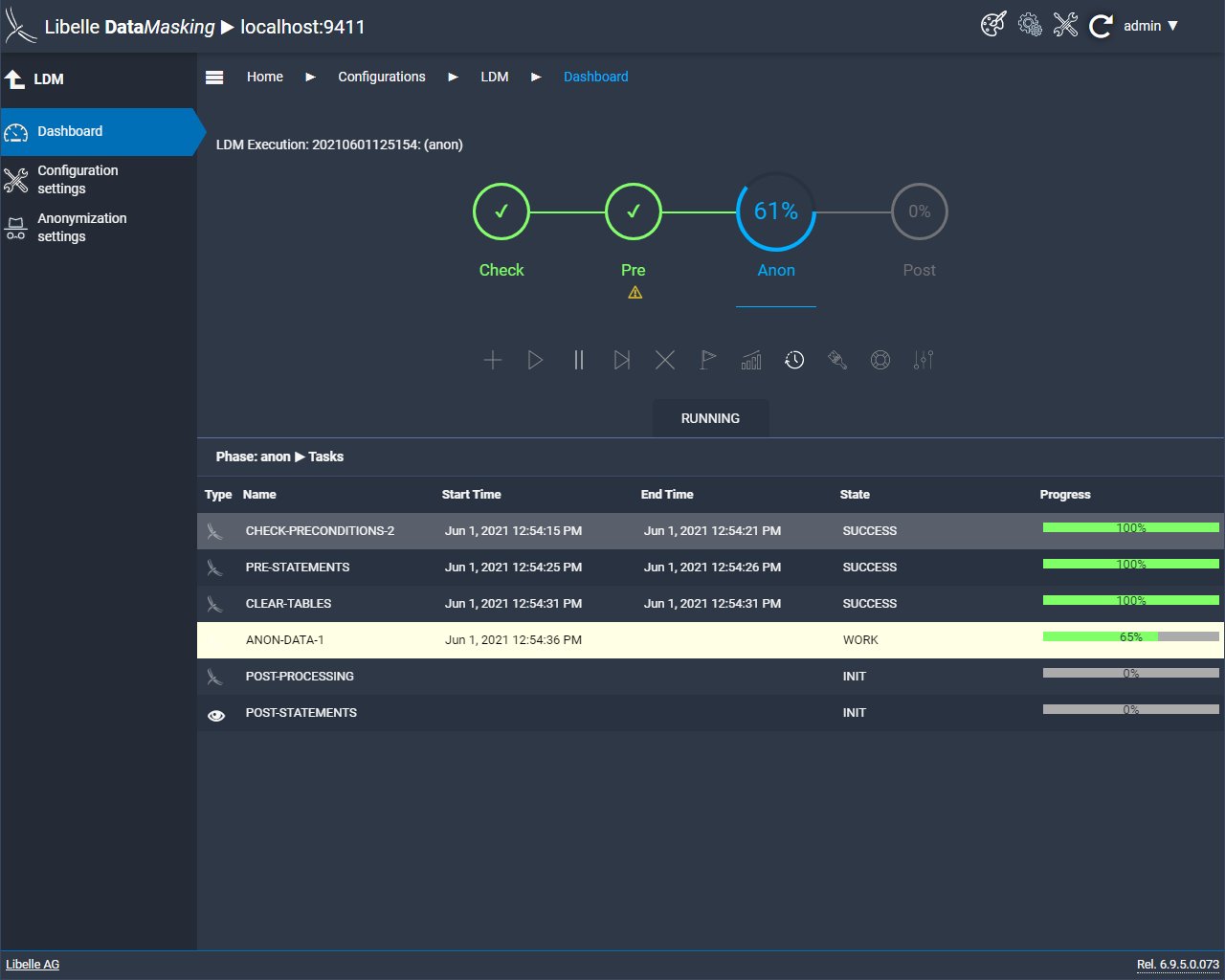
In the anon phase, the supplied and individually set anonymization algorithms are applied. These read the data from the non-production target system and anonymize it with the references provided. The result is realistic-looking and GDPR-compliant data.
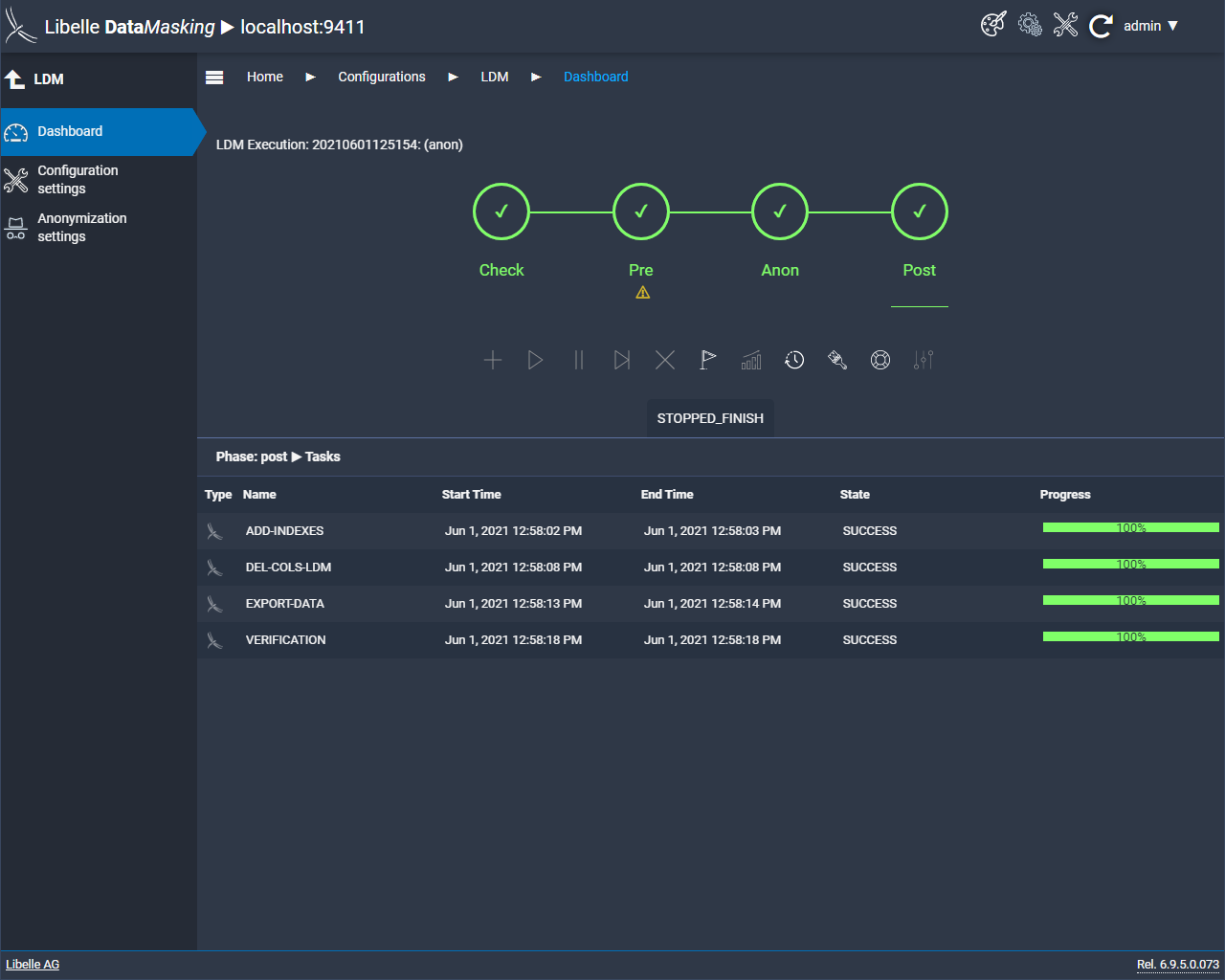
In the last step, the post phase, it is checked whether the consistency of the data has been maintained, a final measure to obtain an optimal result. To give you a complete overview of the anonymization, Libelle DataMasking provides you with a comprehensive final report with all relevant information.
With Libelle DataMasking we provide data masking software that is cloud-ready and can be deployed as a machine image at the following providers:
